
It takes a lot to surprise engineers working on AI, and have them call something magical. ChatGPT stands tall as one of those inventions.
OpenAI unlocked a new world of truly, cognitive, interactive and most importantly general purpose AI with ChatGPT. Suddenly. it was possible for machines to not only understand human language but also cognitively respond, fulfill request, carry out tasks through simple linguistic commands.

As we get more and more familiar with the reality of a truly general purpose AI with ChatGPT, this amazing platform is penetrating deeper and deeper in terms of impact on daily lives.
Estimates reported by CNBC suggest that in the almost 30 year history of internet, ChatGPT is the fastest app (and, by far) to boast of a 100 million strong user-base. Companies in technology sector and beyond are actively exploring possibilities to integrate ChatGPT and other Large Language Models (LLMs) in their business processes to streamline workflows, boost revenue and enhance user experience.
The Hidden Potential of ChatGPT and Text Classification
Working on the integration into custom platforms has also opened up ways for us to learn more and more about the possibilities of pushing the limits of ChatGPT’s versatility. Our community of AI and researchers have started to realize that it is much more than just a chatbot which can talk like a human.
OpenAI has made this possible by generously making a large faction of their platform accessible via a seamless API which supports not only inference of ChatGPT but also training of ChatGPT to perform on your own data. Yes you read it correctly, it is possible to train a custom ChatGPT model for your own problem statement; we’ll get to that.
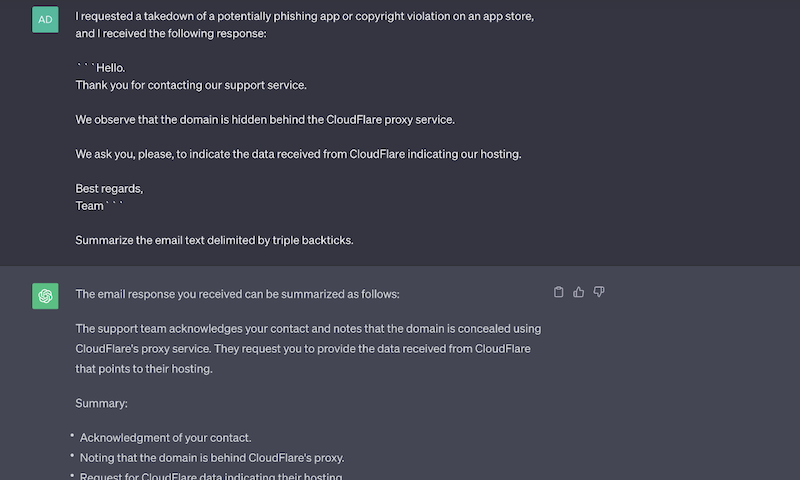
Initially, ChatGPT was thought to be a question-answering or task-completion app that interprets and responds in human language. Consider one of the emails our SOC team received (pictured above) from an app store administrator in response to request for a takedown.
Our team receives responses like these in order of thousands and we label them as “redirected to alternate host” which indicates that app store administrator has requested us to approach alternate host. We ask ChatGPT to analyze the email, and as it can be seen it does a pretty good job. However, this response is still a highly unstructured natural language data and cannot be interpreted by a procedural programming pipeline carrying the overhead of our takedown requests.
Our solution is to fine tune ChatGPT to read the email text provided as a prompt, and generate a single token-based class label, mapped to required labels, and template email response back to the administrator. This kind of fine tuning converts the conversational behavior of ChatGPT to a text classifier which a procedural programming pipeline can interact with seamlessly.

At Bolster AI, we are revamping our fake app store takedown module to protect some of the most popular international brands from relentless phishing attacks they face on non-mainstream app stores. Deploying ChatGPT in the backend of this module is the prime cornerstone in this major revamp, it allows us to streamline our processes by automating even the most human intervention prone tasks and drastically optimize the allocation of SOC resources and response time.
Our workflow demands a close collaboration by our SOC team with administrators of these app stores to remove such malicious content from their platforms. This collaboration is in the form of email conversations where we work with domain administrators to find the best way to remove these apps.
These email conversations require extensive human intervention from SOC analysts and create a bottleneck. Our customers face such phishing attacks in order of thousands every day, and human intervention severely limits our scaling capabilities.
Analyzing multiple instances of takedown workflows has given us an understanding of all kinds of action items our SOC team has to execute in response to these emails from app store domain administrators. This makes handling responses for email correspondences a classification problem.
Learn more about Web LLM Attacks
To make this possible we have combined ChatGPT’s abilities to read text in a general way and clever crafting of the prompts to specify the required classification behavior. The idea is to present the email text as a prompt and train ChatGPT to predict the action item class as the completion. Let’s learn how to fine-tune ChatGPT for a custom use case.
Prerequisites: Accessing an API
OpenAI has made their generative AI suite available through their API launch. OpenAI fashions its API as “text in, text out” interface to allow users to programmatically access their trained GPT model, use them as off the shelf plugin in their existing workflows for both fine tuning and inference.
Accessing this API requires a secret access key, this key can be found here. Retrieving this key would require logging on OpenAI’s platform with a personal account.
Secondly, we need to decide a programming platform to write code to access this API. Python is the go-to programming language to quickly prototype and deploy machine learning applications. While basic Python proficiency is required to write code capable of send API requests, OpenAI has made its API so seamless that anyone with little to no machine learning background can also build an application or pipeline powered by state of the art generative AI.
Setting Up the Right Environment for ChatGPT Training
Now that we have everything we need, let’s start with steps to fine tune a model through OpenAI’s API. The first step is to create an environment and install all the dependencies we need. The dependencies for this project is not heavy, OpenAI’s API does most of the heavy lifting.
Create a project workspace with virtual environment:

Install dependencies:
 :
:Now that our environment is ready, we are set to gather and label our data. With a very minimal setup for the libraries and the machine learning pipeline, as developers we can focus on preparing the data in the best possible way to ensure optimal pattern learning by the LLM.
Data Collection and Preparation
Arguably the most critical factor to determine the performance levels from an LLM like OpenAI’s ChatGPT, is to prepare a dataset which is diverse and convey the intent of learning to the model in the optimal way. It’s important to ensure that data is appropriately formulated on the dataset level as well as datapoint level.
The second part is important as we are dealing with text data, and as ChatGPT even in case of fine-tuning is still a general purpose model. The prompts presented to it need to be carefully formulated and should convey the intent of learning clearly.
On the dataset level, to ensure generalizability, we need to diversify data points and to eliminate the possibility of bias, the data points need to be distributed among the classes uniformly. Recommendation is to gather at least 200 datapoints for each class.
On datapoint level, prompt needs to have abundant clarity. We arrange our prompts to have character guards to demarcate between the prompt and the completion required from the LLM. Our prompt is consists of the email text and the class label as the completion separated by the character guard. We add “\n\n###\n\n” to the end of the email text to be classified, and append the class label as the completion.
Our classification dataset covers about 9 classes to represent action items our SOC teams constantly execute to make sure domain administrator have everything they need to remove malicious content form their platform.
Following are some of example classes and the labels associated with these classes, these labels are interpreted as the completion token by the LLM. We have 10 classes in total to take care of different scenarios.

Following are the examples of real datapoints we used to fine tune ChatGPT’s curie model for our custom use case:

Once we have gathered the labeled data points as above in two different files training_data.json and validation_data.json, we need to convert the dataset from JSON format to a different JSONL dataset. Following is what JSONL from same datapoints look like.
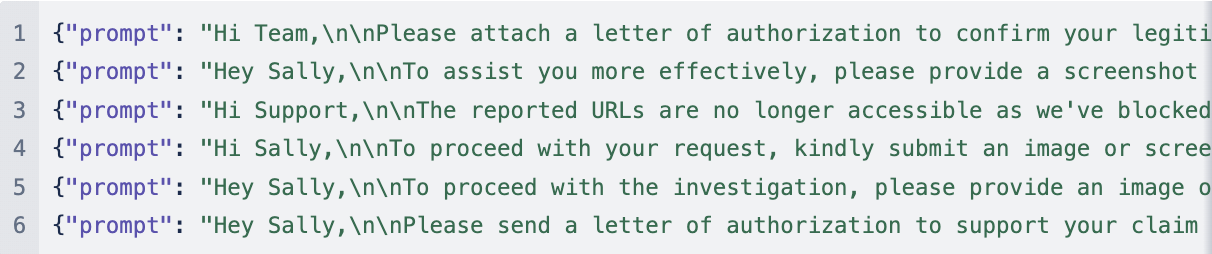
To convert the JSON file to JSONL, we need to process this data through python and dump the data into new JSONL file. Following is the python code in create_data.py achieves this for training data.

Run this file to create the JSONL files with following terminal command:

Same process can be followed for validation data by replacing the file name of the file. A no-code way to convert data to JSONL is also provided by OpenAI’s API. Use the following terminal command to convert data to JSONL.

OpenAI has made prepare_data to be a power tool, it can analyze the dataset fed to it, can find duplicate data points and also remove them if requested, create training validation split and finally dump the data to JSONL files.
Fine Tuning the ChatGPT
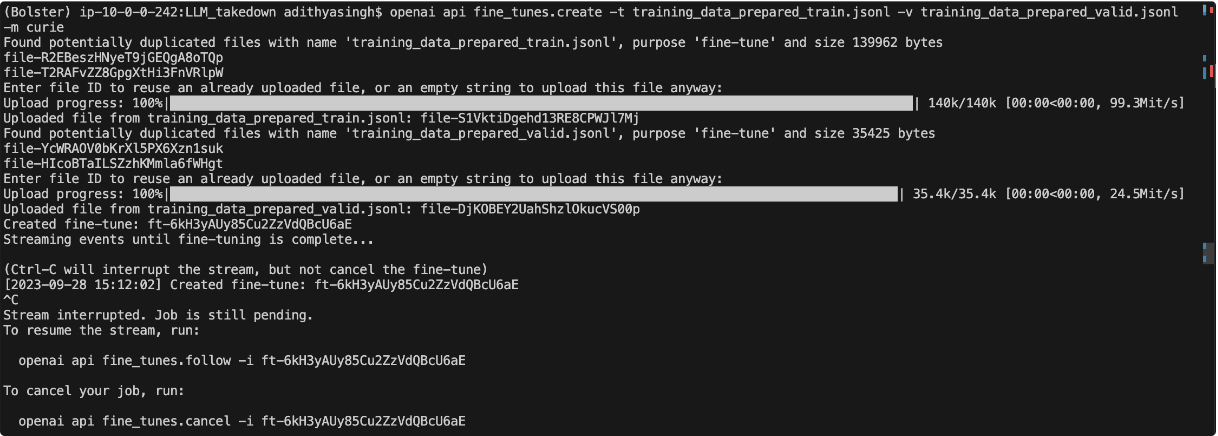
Now that our data is ready, we are finally ready to create a fine tuning job on the OpenAI’s server. The API is powerful enough to upload the JSONL file, create a training job and queue it with other jobs that have been requested by ChatGPT developers on its servers.
To start a fine tuning job with our prepared data, execute the following terminal command:

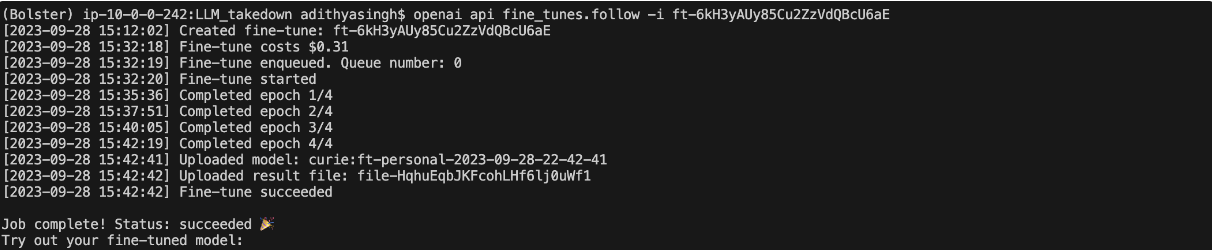
This command queues the training job on the OpenAI servers, and we’re done. The queue can take up to 6 hours to clear depending on how busy servers are. OpenAI will also display the instructions to check the status of the training job using an ID. Following is an example run via OpenAI API.
After the fine tuning job is complete, OpenAI will provide the trained model’s name, this model’s name can also be retrieved by using the fine tuning job ID with the following command:

Putting Your Custom ChatGPT Model to Use: Unleash the Magic
Once the model is fine tuned, it’s now time to put a test to its capabilities. For this let’s create a python script, which will call the OpenAI API with text data. With the Python bindings of the API, it is possible to use the fine tuned model off the shelf as a plugin to any software pipeline with a simple method call.
We need to create two methods, one will hit the OpenAI’s API and retrieve the response generated by the fine tuned model. It is critical to formulate the prompt which are in same format as the prompts used during the fine tuning. The prompt should be appended with the character guard “\n\n###\n\n” to indicate the end. The number of tokens to be retrieved determines the length of the text response the model is required to generate. Since the learning intent of the model is classification, model should only generate a single token indicating the class label with a leading whitespace.
Create a python script, chatGPT_client.py, and write code for the function getGPTResponse. OpenAI allows access to the trained model via its openai.Completion API. It needs the model name, the prompt text and the max tokens retrieved, lets pass it to be 1 to get class label.

The openai.Completion.create function returns a response in JSON format, following is an example:
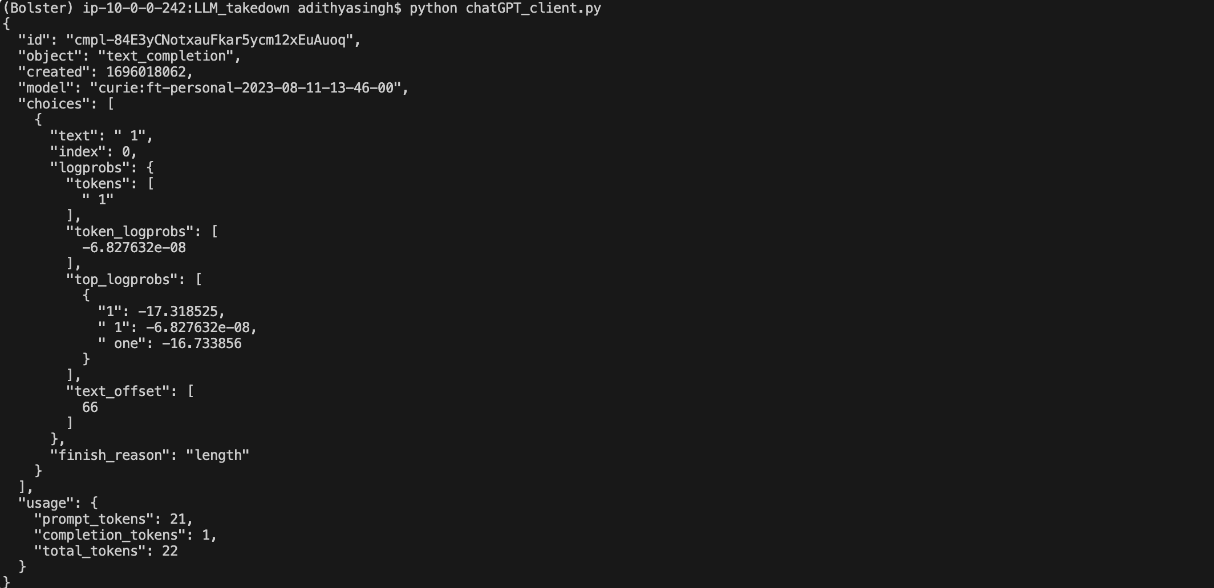

The parseResponse function takes in the JSON response from the API and extracts class label. The class label is directly mapped to the action items that correspond to the SOC operations necessary to ensure smooth takedown.
Finally now the code to call this pipeline:

And there it is, we have created a simple python client capable of requesting a classification from custom fine-tuned curie model by OpenAI, which we trained for our custom use case.
Using ChatGPT to Protect Your Business
OpenAI has made it so seamless to utilize the knowledge possessed by a general purpose AI and tune it to process natural language to a custom use case. It is now possible to create apps that can use the generalization capability of a huge model like GPT in the backend. Not only this, but the API provided has a very cost effective pricing attached to it, as it charges $0.0004 / 1K tokens during the training and $0.0016 / 1K tokens via API requests during the inference phase.
To learn more about how you can use AI to protect your business from cyber attacks, request a demo with Bolster, or talk to a member of our team today.








